Interview
数据结构
1 . ArrayList 和 LinkedList 区别?
ArrayList 是一个可改变大小的数组。当更多的元素加入到 ArrayList 中时,其大小将会动 态地增长。内部的元素可以直接通过 get 与 set 方法进行访问,因为 ArrayList 本质上就 是一个数组。 LinkedList 是一个双链表,在添加和删除元素时具有比 ArrayList 更好的性能.但在 get 与 set 方面弱于 ArrayList。当然,这些对比都是指数据量很大或者操作很频繁的情况下的对 比,如果数据和运算量很小,那么对比将失去意义。
2 .哈希表的存储原理
根据键值对(k/v)直接访问的数据结构。记录存储位置=f(k),对应关系 f 称为散列函数(hash 函数),散列表就是把 k 通过固定的哈希函数转换成一个整型数字,然后将整型数字对数组长度取余,取余结果作为数组下标,v 存储在该数字为下标的数组空间中,所以查询速度很快
哈希表的扩容机制是怎样的?
装载因子=元素个数/散列表长度,当前表的实际装载因子达到默认的负载因子值时就触发哈希表的扩容,以 2 倍大小进行扩容。
判断是否相同已经有 equals 方法为什么还需要 hashcode 方法?
因为 equals 方法的效率远不如 hashcode 方法,同时 equals 方法是完全可靠的,而仅基于 hashcode 是不完全可靠的,所以 java 中提供了这 2 个方法的重写,先用 hashcode 比较,如果相同则再用 equals 比较。
哈希冲突是指什么?
不同的 key 经由哈希函数映射到了相同的位置上,造成冲突,如果冲突比较严重就会影响哈希表性能。一般采用 4 种方式解决,开放定址法、链地址法、再哈希法、建立公共溢出区。
常见的 hash 算法及冲突的解决 在具体介绍 HashMap 如何使用散列函数之前,先简单介绍一下常见的 hash 算法,以便于你可以更加系统地了解它。
a. 直接定址法:直接以关键字 k 或者 k 加上某个常数(k+c)作为哈希地址(H(k)=ak+b)。
b. 数字分析法:提取关键字中取值比较均匀的数字作为哈希地址(如一组出生日期,相较于年-月,月-日的差别要大得多,可以降低冲突概率)
c. 分段叠加法:按照哈希表地址位数将关键字分成位数相等的几部分,其中最后一部分可以比较短。然后将这几部分相加,舍弃最高进位后的结果就是该关键字的哈希地址。
d. 平方取中法:如果关键字各个部分分布都不均匀的话,可以先求出它的平方值,然后按照需求取中间的几位作为哈希地址。
e. 伪随机数法:选择一随机函数,取关键字的随机值作为散列地址,通常用于关键字长度不同的场合。
f. 除留余数法:用关键字 k 除以某个不大于哈希表长度 m 的数 p,将所得余数作为哈希表地址(H(k)=k%p, p<=m; p 一般取 m 或素数)。
上文已经说到,不同的输入通过散列函数,有可能会得到相同的输出。既然通过不同的输入可以得到相同的输出,那么如果发生冲突了怎么办?比如在 HashMap 中,如果两个不同的 key 计算得出的散列值相同,后来的岂不是会覆盖先来的?不用担心,解决 hash 冲突的方法也是有的,常见的有:
a. 链地址法:将哈希表的每个单元作为链表的头结点,所有哈希地址为 i 的元素构成一个同义词链表。即发生冲突时就把该关键字链在以该单元为头结点的链表的尾部。
b. 开放定址法:即发生冲突时,去寻找下一个空的哈希地址。只要哈希表足够大,总能找到空的哈希地址。
c. 再哈希法:即发生冲突时,由其他的函数再计算一次哈希值。
d. 建立公共溢出区:将哈希表分为基本表和溢出表,发生冲突时,将冲突的元素放入溢出表。
网络
OSI 七层模型及各层的协议包含哪些?
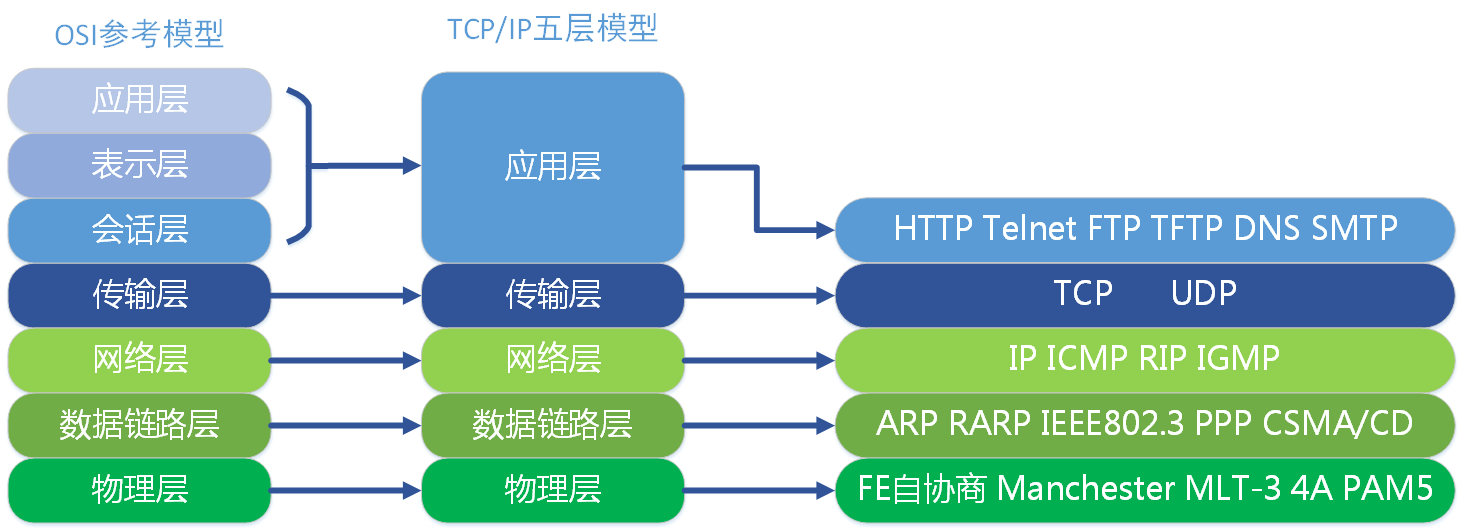
说下进程间通信,以及各自的区别
进程间通信是指在不同进程之间传播或交换信息。方式通常有管道(包括无名管道和命名 管道)、消息队列、信号量、共享存储、Socket、Streams 等。
JAVA
IOC 的优点是什么?
IOC 或 依赖注入把应用的代码量降到最低。它使应用容易测试,单元测试不 再需要单例和 JNDI 查找机制。最小的代价和最小的侵入性使松散耦合得以实 现。IOC 容器支持加载服务时的饿汉式初始化和懒加载。
Spring AOP 和 AspectJ 什么区别
Spring AOP 是动态代理,AspectJ 是静态代理,一个运行时织入,一个编译时织入性能会更好一些,Spring AOP 是方法级织入,AspectJ 提供完整的 AOP 解决方案,支持字段、方法、构造函数等,更强大也更复杂。
Spring AOP 常用 2 种,JDK 动态代理和 CGLIB 动态代理,JDK 动态代理必须通过接口实现,是 spring framework 的默认方式,CGLIB 是通过字节码拼接实现,springboot2.x 默认使用 CGLIB。
springboot 设置使用 JDK 动态代理的方式:spring.aop.proxy-target-class=false
springMVC 与 springBoot 什么区别
Spring 包含了 SpringMVC,而 SpringBoot 又包含了 Spring 或者说是在 Spring 的基础上做得一个扩展
为什么要用 SpringBoot
提供嵌入式容器支持
使用命令 java -jar 独立运行 jar
在外部容器中部署时,可以选择排除依赖关系以避免潜在的 jar 冲突
部署时灵活指定配置文件的选项
用于集成测试的随机端口生成
总结就是快速开发,快速整合,配置简化、内嵌服务容器。
SpringBoot 配置文件的加载顺序
由 jar 包外向 jar 包内进行寻找 优先加载带 profile jar 包外部的 application-{profile}.properties 或 application.yml(带 spring.profile 配置文件 jar 包内部的 application-{profile}.properties 或 application.yml(带 spring.profile 配置文件 再来加载不带 profile jar 包外部的 application.properties 或 application.yml(不带 spring.profile 配置文件 jar 包内部的 application.properties 或 application.yml(不带 spring.profile 配置文件
什么情况会造成内存泄漏?
在 Java 中,内存泄漏就是存在一些被分配的对象,这些对象有下面两个特点: 首先,这些对象是可达的,即在有向图中,存在通路可以与其相连; 其次,这些对象是无用的,即程序以后不会再使用这些对象。如果对象满足这两个条件, 这些对象就可以判定为 Java 中的内存泄漏,这些对象不会被 GC 所回收,然而它却占用内 存。
数据库
1 .说一下 Innodb 和 MySIAM 的区别?
MyISAM 类型不支持事务处理等高级处理,而 InnoDB 类型支持。MyISAM 类型的表强 调的是性能,其执行数度比 InnoDB 类型更快,但是不提供事务支持,而 InnoDB 提供事 务支持以及外部键等高级数据库功能。 InnoDB 不支持 FULLTEXT 类型的索引。 InnoDB 中不保存表的具体行数,也就是说,执行 select count() from table 时, InnoDB 要扫描一遍整个表来计算有多少行,但是 MyISAM 只要简单的读出保存好的行数 即可。注意的是,当 count()语句包含 where 条件时,两种表的操作是一样的。 对于 AUTO_INCREMENT 类型的字段,InnoDB 中必须包含只有该字段的索引,但是在 MyISAM 表中,可以和其他字段一起建立联合索引。 DELETE FROM table 时,InnoDB 不会重新建立表,而是一行一行的删除。 LOAD TABLE FROM MASTER 操作对 InnoDB 是不起作用的,解决方法是首先把 InnoDB 表改成 MyISAM 表,导入数据后再改成 InnoDB 表,但是对于使用的额外的 InnoDB 特性(例如外键)的表不适用。
幻读是什么,通过什么方式解决的?
幻读可能会出现主键冲突确不知道原因的情况。mysql InnoDB 通过 MVCC(多版本并发控制)解决该问题。
mysql 插入数据的几种形式
replace into 表示插入替换数据,需求表中有 PrimaryKey,或者 unique 索引,如果数据库已经存在数据,则用新数据替换,如果没有数据效果则和 insert into 一样
insert ignore 表示,如果表中如果已经存在相同的记录,则忽略当前新数据
mysql int(1),int(5)什么区别
int 后长度数字是配合 zerofill 进行补零用,int(1)也可以插入 10000
select * from xxx where xxx for update 是行锁还是表锁
如果使用了索引就是行锁,否则是表锁
mysql 如何执行 sql 脚本的
用户发送请求,服务通过数据库连接池提交 sql 脚本,mysql 得到脚本后传给 sql 接口,然后调用 sql 解析器识别脚本,查询优化器进行优化,形成执行计划,执行器调用执行引擎接口完成脚本执行
如何优化 MySQL?
提供嵌入式容器支持
使用命令 java -jar 独立运行 jar
在外部容器中部署时,可以选择排除依赖关系以避免潜在的 jar 冲突
部署时灵活指定配置文件的选项
用于集成测试的随机端口生成
架构思维
MVVM 是为了解决什么问题产生的?
任何一个模式的出现,一定为了解决软件工程中某个特定的痛点,要么是为了提高开发效率,缩短软件开发周期;要么是为了提高软件的稳定性、可扩展性;要么是为了提高软件的运行性能等等 。
MVVM 是为了让界面设计师专注于界面元素和交互,从而能够设计出让用户欣喜若狂的产品;让开发者专注于逻辑,完全脱离 UI,从而能够保证程序的稳定性、可扩展性、和高性能。由于界面设计和业务完全分离,使得更换界面变得简单,调整业务逻辑也不会对界面产生严重的影响;另一方面,也使得我们可以单独对业务进行单元测试。