如何一次导出百万行数据
原始需求:用户在 UI 界面上点击全部导出按钮,就能导出所有商品数据。
咋一看,这个需求挺简单的。
但如果我告诉你,导出的记录条数,可能有一百多万,甚至两百万呢?
这时你可能会倒吸一口气。
因为你可能会面临如下问题:
如果同步导数据,接口很容易超时。 如果把所有数据一次性装载到内存,很容易引起 OOM。 数据量太大 sql 语句必定很慢。 相同商品编号的数据要放到一起。 如果走异步,如何通知用户导出结果? 如果 excel 文件太大,目标用户打不开怎么办? 我们要如何才能解决这些问题,实现一个百万级别的 excel 数据快速导出功能呢?
1.异步处理
做一个 MySQL 百万数据级别的 excel 导出功能,如果走接口同步导出,该接口肯定会非常容易超时。
因此,我们在做系统设计的时候,第一选择应该是接口走异步处理。
说起异步处理,其实有很多种,比如:使用开启一个线程,或者使用线程池,或者使用 job,或者使用 mq 等。
为了防止服务重启时数据的丢失问题,我们大多数情况下,会使用 job 或者 mq 来实现异步功能。
1.1 使用 job 如果使用 job 的话,需要增加一张执行任务表,记录每次的导出任务。
用户点击全部导出按钮,会调用一个后端接口,该接口会向表中写入一条记录,该记录的状态为:待执行。
有个 job,每隔一段时间(比如:5 分钟),扫描一次执行任务表,查出所有状态是待执行的记录。
然后遍历这些记录,挨个执行。
需要注意的是:如果用 job 的话,要避免重复执行的情况。比如 job 每隔 5 分钟执行一次,但如果数据导出的功能所花费的时间超过了 5 分钟,在一个 job 周期内执行不完,就会被下一个 job 执行周期执行。
所以使用 job 时可能会出现重复执行的情况。
为了防止 job 重复执行的情况,该执行任务需要增加一个执行中的状态。
具体的状态变化如下:
执行任务被刚记录到执行任务表,是待执行状态。 当 job 第一次执行该执行任务时,该记录再数据库中的状态改为:执行中。 当 job 跑完了,该记录的状态变成:完成或失败。 这样导出数据的功能,在第一个 job 周期内执行不完,在第二次 job 执行时,查询待处理状态,并不会查询出执行中状态的数据,也就是说不会重复执行。
此外,使用 job 还有一个硬伤即:它不是立马执行的,有一定的延迟。
如果对时间不太敏感的业务场景,可以考虑使用该方案。
1.2 使用 mq 用户点击全部导出按钮,会调用一个后端接口,该接口会向 mq 服务端,发送一条 mq 消息。
有个专门的 mq 消费者,消费该消息,然后就可以实现 excel 的数据导出了。
相较于 job 方案,使用 mq 方案的话,实时性更好一些。
对于 mq 消费者处理失败的情况,可以增加补偿机制,自动发起重试。
RocketMQ 自带了失败重试功能,如果失败次数超过了一定的阀值,则会将该消息自动放入死信队列。
2.使用 easyexcel
我们知道在 Java 中解析和生成 Excel,比较有名的框架有 Apache POI 和 jxl。
但它们都存在一个严重的问题就是:非常耗内存,POI 有一套 SAX 模式的 API 可以一定程度的解决一些内存溢出的问题,但 POI 还是有一些缺陷,比如 07 版 Excel 解压缩以及解压后存储都是在内存中完成的,内存消耗依然很大。
百万级别的 excel 数据导出功能,如果使用传统的 Apache POI 框架去处理,可能会消耗很大的内存,容易引发 OOM 问题。
而 easyexcel 重写了 POI 对 07 版 Excel 的解析,之前一个 3M 的 excel 用 POI sax 解析,需要 100M 左右内存,如果改用 easyexcel 可以降低到几 M,并且再大的 Excel 也不会出现内存溢出;03 版依赖 POI 的 sax 模式,在上层做了模型转换的封装,让使用者更加简单方便。
需要在 maven 的 pom.xml 文件中引入 easyexcel 的 jar 包:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>3.0.2</version>
</dependency>
之后,使用起来非常方便。
读 excel 数据非常方便:
@Test
public void simpleRead() {
String fileName = TestFileUtil.getPath() + "demo" + File.separator + "demo.xlsx";
// 这里 需要指定读用哪个 class 去读,然后读取第一个 sheet 文件流会自动关闭
EasyExcel.read(fileName, DemoData.class, new DemoDataListener()).sheet().doRead();
}
写 excel 数据也非常方便:
@Test
public void simpleWrite() {
String fileName = TestFileUtil.getPath() + "write" + System.currentTimeMillis() + ".xlsx";
// 这里 需要指定写用哪个 class 去读,然后写到第一个 sheet,名字为模板 然后文件流会自动关闭
// 如果这里想使用 03 则 传入 excelType 参数即可
EasyExcel.write(fileName, DemoData.class).sheet("模板").doWrite(data());
}
easyexcel 能大大减少占用内存的主要原因是:在解析 Excel 时没有将文件数据一次性全部加载到内存中,而是从磁盘上一行行读取数据,逐个解析。
3.分页查询
百万级别的数据,从数据库一次性查询出来,是一件非常耗时的工作。
即使我们可以从数据库中一次性查询出所有数据,没出现连接超时问题,这么多的数据全部加载到应用服务的内存中,也有可能会导致应用服务出现 OOM 问题。
因此,我们从数据库中查询数据时,有必要使用分页查询。比如:每页 5000 条记录,分为 200 页查询。
public Page<User> searchUser(SearchModel searchModel) {
List<User> userList = userMapper.searchUser(searchModel);
Page<User> pageResponse = Page.create(userList, searchModel);
pageResponse.setTotal(userMapper.searchUserCount(searchModel));
return pageResponse;
}
每页大小 pageSize 和页码 pageNo,是 SearchModel 类中的成员变量,在创建 searchModel 对象时,可以设置设置这两个参数。
然后在 Mybatis 的 sql 文件中,通过 limit 语句实现分页功能:
limit #{pageStart}, #{pageSize} 其中的 pagetStart 参数,是通过 pageNo 和 pageSize 动态计算出来的,比如:
pageStart = (pageNo - 1) * pageSize;
4.多个 sheet
我们知道,excel 对一个 sheet 存放的最大数据量,是有做限制的,一个 sheet 最多可以保存 1048576 行数据。否则在保存数据时会直接报错:
invalid row number (1048576) outside allowable range (0..1048575) 如果你想导出一百万以上的数据,excel 的一个 sheet 肯定是存放不下的。图片
因此我们需要把数据保存到多个 sheet 中。图片
5.计算 limit 的起始位置
我之前说过,我们一般是通过 limit 语句来实现分页查询功能的:
limit #{pageStart}, #{pageSize} 其中的 pagetStart 参数,是通过 pageNo 和 pageSize 动态计算出来的,比如:
pageStart = (pageNo - 1) * pageSize; 如果只有一个 sheet 可以这么玩,但如果有多个 sheet 就会有问题。因此,我们需要重新计算 limit 的起始位置。
例如:
ExcelWriter excelWriter = EasyExcelFactory.write(out).build();
int totalPage = searchUserTotalPage(searchModel);
if(totalPage > 0) {
Page<User> page = Page.create(searchModel);
int sheet = (totalPage % maxSheetCount == 0) ? totalPage / maxSheetCount: (totalPage / maxSheetCount) + 1;
for(int i=0;i<sheet;i++) {
WriterSheet writeSheet = buildSheet(i,"sheet"+i);
int startPageNo = i*(maxSheetCount/pageSize)+1;
int endPageNo = (i+1)*(maxSheetCount/pageSize);
while(page.getPageNo()>=startPageNo && page.getPageNo()<=endPageNo) {
page = searchUser(searchModel);
if(CollectionUtils.isEmpty(page.getList())) {
break;
}
excelWriter.write(page.getList(),writeSheet);
page.setPageNo(page.getPageNo()+1);
}
}
}
这样就能实现分页查询,将数据导出到不同的 excel 的 sheet 当中。
6.文件上传到 OSS
由于现在我们导出 excel 数据的方案改成了异步,所以没法直接将 excel 文件,同步返回给用户。
因此我们需要先将 excel 文件存放到一个地方,当用户有需要时,可以访问到。
这时,我们可以直接将文件上传到 OSS 文件服务器上。
通过 OSS 提供的上传接口,将 excel 上传成功后,会返回文件名称和访问路径。
我们可以将 excel 名称和访问路径保存到表中,这样的话,后面就可以直接通过浏览器,访问远程 excel 文件了。
而如果将 excel 文件保存到应用服务器,可能会占用比较多的磁盘空间。
一般建议将应用服务器和文件服务器分开,应用服务器需要更多的内存资源或者 CPU 资源,而文件服务器需要更多的磁盘资源。
7.通过 WebSocket 推送通知
通过上面的功能已经导出了 excel 文件,并且上传到了 OSS 文件服务器上。
接下来的任务是要本次 excel 导出结果,成功还是失败,通知目标用户。
有种做法是在页面上提示:正在导出 excel 数据,请耐心等待。
然后用户可以主动刷新当前页面,获取本地导出 excel 的结果。
但这种用户交互功能,不太友好。
还有一种方式是通过 webSocket 建立长连接,进行实时通知推送。
如果你使用了 SpringBoot 框架,可以直接引入 webSocket 的相关 jar 包:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-websocket</artifactId>
</dependency>
使用起来挺方便的。
我们可以加一张专门的通知表,记录通过 webSocket 推送的通知的标题、用户、附件地址、阅读状态、类型等信息。
能更好的追溯通知记录。
webSocket 给客户端推送一个通知之后,用户的右上角的收件箱上,实时出现了一个小窗口,提示本次导出 excel 功能是成功还是失败,并且有文件下载链接。
当前通知的阅读状态是未读。
用户点击该窗口,可以看到通知的详细内容,然后通知状态变成已读。
8.总条数可配置
我们在做导百万级数据这个需求时,是给用户用的,也有可能是给运营同学用的。
其实我们应该站在实际用户的角度出发,去思考一下,这个需求是否合理。
用户拿到这个百万级别的 excel 文件,到底有什么用途,在他们的电脑上能否打开该 excel 文件,电脑是否会出现太大的卡顿了,导致文件使用不了。
如果该功能上线之后,真的发生发生这些情况,那么导出 excel 也没有啥意义了。
因此,非常有必要把记录的总条数,做成可配置的,可以根据用户的实际情况调整这个配置。
比如:用户发现 excel 中有 50 万的数据,可以正常访问和操作 excel,这时候我们可以将总条数调整成 500000,把多余的数据截取掉。
其实,在用户的操作界面,增加更多的查询条件,用户通过修改查询条件,多次导数据,可以实现将所有数据都导出的功能,这样可能更合理一些。
此外,分页查询时,每页的大小,也建议做成可配置的。
通过总条数和每页大小,可以动态调整记录数量和分页查询次数,有助于更好满足用户的需求。
9.order by 商品编号
之前的需求是要将相同商品编号的数据放到一起。
例如:
| 编号 | 商品名称 | 仓库名称 | 价格 |
|---|---|---|---|
| 1 | 笔记本 | 北京仓 | 7234 |
| 1 | 笔记本 | 上海仓 | 7235 |
| 1 | 笔记本 | 武汉仓 | 7236 |
| 2 | 平板电脑 | 成都仓 | 7236 |
| 2 | 平板电脑 | 大连仓 | 3339 |
但我们做了分页查询的功能,没法将数据一次性查询出来,直接在 Java 内存中分组或者排序。
因此,我们需要考虑在 sql 语句中使用 order by 商品编号,先把数据排好顺序,再查询出数据,这样就能将相同商品编号,仓库不同的数据放到一起。
此外,还有一种情况需要考虑一下,通过配置的总记录数将全部数据做了截取。
但如果最后一个商品编号在最后一页中没有查询完,可能会导致导出的最后一个商品的数据不完整。
因此,我们需要在程序中处理一下,将最后一个商品删除。
但加了 order by 关键字进行排序之后,如果查询 sql 中 join 了很多张表,可能会导致查询性能变差。
那么,该怎么办呢?
总结 最后用两张图,总结一下 excel 异步导数据的流程。
如果是使用 mq 导数据: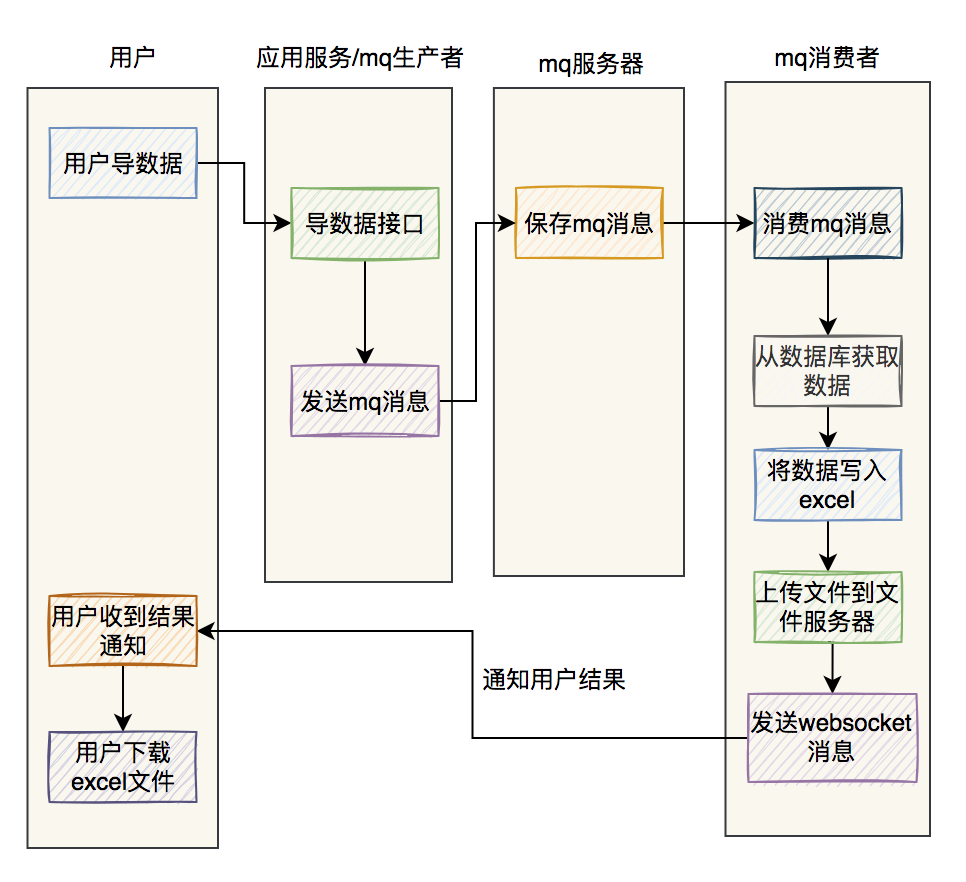
如果是使用 job 导数据: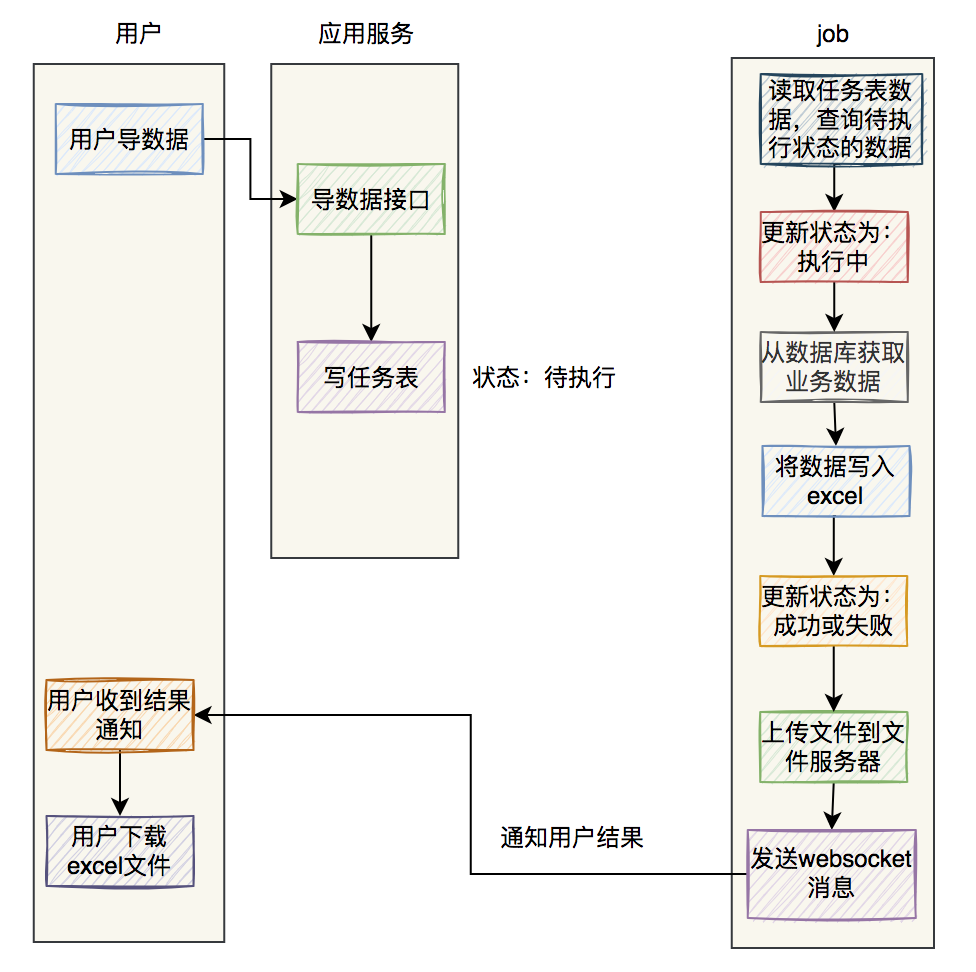
这两种方式都可以,可以根据实际情况选择使用。
欢迎来访
- 有问题欢迎留言或加交流qq:825121848
- 转载请注明出处
- 请小编喝茶~
